
Privacy, Security, and Reliability Aspects in Trading Personal Data for Businesses
This post is for companies who are dealing with the personal data of users for business purposes. As we know, data has become an integral part of almost every industry, such as social media, healthcare, e-commerce, and government. With the advancements in digital technology and the proliferation of online services, data is growing at a tremendous pace.

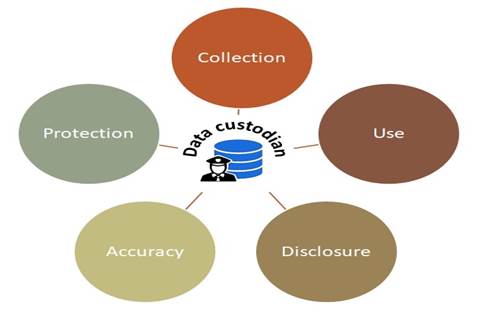
Data often contains person-specific information. A data custodian who holds person-specific information must be responsible for managing the use, disclosure, accuracy, and privacy protection of collected data.
Privacy is a fundamental human right, and for this several, privacy legislation and regulations such as Personal Information Protection and Electronic Documents Act (PIPEDA) by Canada, Health Insurance Portability and Accountability Act (HIPAA) by the United States, and General Data Protection Regulation (GDPR) by the European Union, across the globe, have been imposed for protecting personal data. These legal and regulatory frameworks enforce companies or businesses who deal with personal data must ensure the protection of individuals by removing identifiable information from the data they own.

Recent studies show that companies who either do not meet the legal and regulatory requirements of privacy protection or lack the required skills for privacy protection have faced litigations from individuals whose privacy were breached and subsequently paid the fines and penalties for compensation. It can extend to the loss of reputation and goodwill in the market for those companies or businesses.

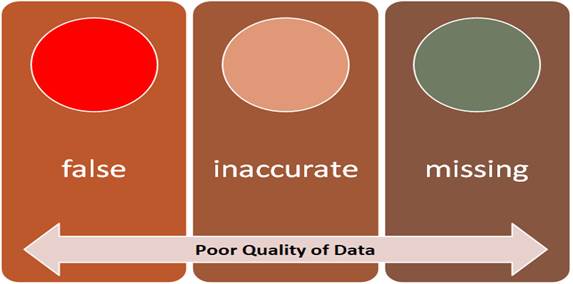
Another aspect is data reliability for businesses. According to a recent survey, organizations in the U.S. estimate that 33% of their customer data are inaccurate. This skepticism about data elicits the increased risk of noncompliance and regulatory penalties. The study by IBM estimated that $3.1 trillion of the U.S.’s GDP is lost due to poor quality data. Organizations may mitigate these potential risks by taking appropriate measures regarding the quality of their data, leading to more reliable analysis and decision making.
Research communities have investigated the problem of exchanging data from the perspective of ensuring confidentiality and integrity. They have proposed solutions to provide prevention from unauthorized use and modification when data is in transit. However, the existing works do not address the problem of verifying the correctness of private data if any party provides false data.
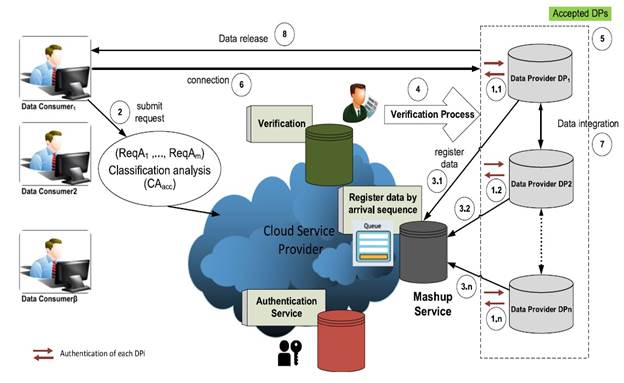
The figure below provides an overview of the proposed trust mechanism, in which data providers, data consumers, and cloud service providers (CSPs) are the main entities. Data providers collect person-specific information from customers and intend to participate in the data mashup for generating more profit by competing with peer data providers, data consumers perform data analysis on the received data, and the CSP is a semi-trusted arbitrator between data providers and data consumers. The CSP manages three key services: authentication, mashup coordination, and data verification. These services are run on a cloud server (CS) by the CSP.
- First, each data provider has to pass the authentication phase to prove their identity.
- Second, data consumers submit their data requests (i.e., attributes) to the CSP.
- Third, data providers register their available data attributes on the registry hosted by the mashup service; each data attribute is assigned a sequence number based on its arrival.
- Fourth, the verification process is run to detect false or incorrect data and to determine the trustworthiness of each data provider.
- Fifth, this process results in determining the accepted data providers.
- Sixth, the CSP connects the group of accepted data providers with the data consumer to serve its demand. This is done by the mashup service that determines the group of data providers whose data can collectively fulfill the demand of a data consumer.
- Seventh, the data providers quantify their costs and benefits using joint privacy requirements and integrate their data over the cloud.
- Finally, the anonymous integrated data is released to the data consumer.
Example: Suppose that there is a cloud-based data market, where data consumers can place their data mining requests and data providers compete with each other to contribute their data with the goal of fulfilling the requests for monetary reward. Consider the 12 raw data records in the table below, where each record corresponds to the personal information of an individual. The three data providers own different yet overlapping sets of attributes over the 12 records.
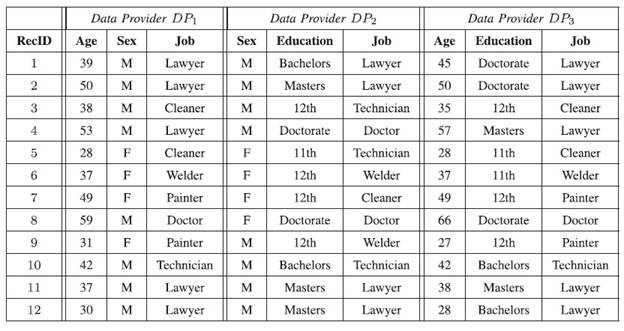
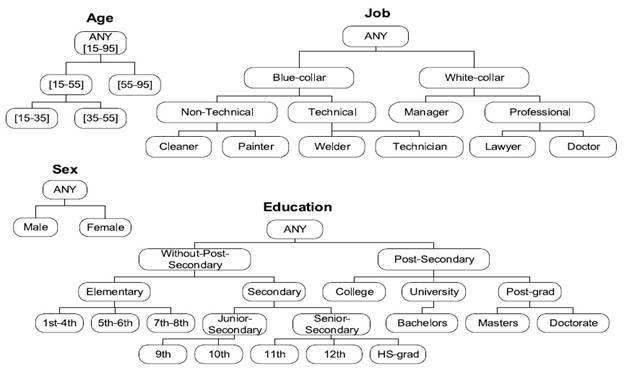
Since the data providers collect data from different channels, it is quite possible that their data conflict with each other, as illustrated in the table. According to the predefined generalization hierarchy of the attributes in the figure below, the individuals in the table can be generalized to two groups: Non-Technical and Technical. Suppose that a data consumer wants to perform a data analysis that depends on the Non-Technical and Technical groups. Yet, the inconsistent, conflicting, or even inaccurate data may mislead the analysis result. For example, DP1 and DP3 state that the individuals in {Rec#3, 5} are Cleaner, while DP2 states that they are Technician. A similar conflict can be seen in Rec#9, where DP1 and DP3 provide the Job as Painter, and DP2 provides the Job as Welder. In this example, the Job attribute on {Rec#3, 5, 9} has two different values that are categorized as Non-Technical and Technical, respectively. These inconsistencies significantly impact the quality of data analysis.
The article proposes a novel twofold solution to address the critical issues of data trustworthiness, privacy protection, and profit distribution for cloud-based data integration services.
- It presents the first information entropy-based trust computation algorithm, IEB_Trust, that allows a semi-trusted arbitrator to detect the covert behavior of a dishonest data provider, evaluates the trustworthiness of the participating data providers by a trust metric, and chooses the qualified providers for data mashup.
- It incorporates the Vickrey-Clarke-Groves (VCG) auction mechanism for the valuation of data providers' attributes into the data mashup process. The monetary shares for the chosen data providers are calculated from their contribution in information utility and their attained trust scores over the differentially private release of the integrated dataset under the mutually agreed privacy requirements.
IEB_Trust verifies the correctness of data from untrusted multiple data providers, who own overlapping attributes for the same set of records. It is assumed that the data providers are competitors, who intend to maximize their profits. The data providers consider as dishonest anyone who may arbitrarily attempt to provide false data to get a larger monetary share from their participation. The method employs information gain as a criterion for splitting attributes based on the concept introduced by Claude Shannon on information theory. Information entropy has been widely used in machine learning tools and decision-making systems. Trust score is a metric for assessing the trustworthiness of each data provider. It is computed in an iterative manner on each challenge attribute. A data provider qualifies on the majority gains a positive weight in his trust score. On the other hand, a disqualified data provider is penalized with a negative weight in the trust score. Finally, both positive and negative weights are aggregated to determine the final trust score of each data provider.
Security Properties: The following are the security properties of the IEB_Trust algorithm.
- Security Against Covert Adversaries: In the context of the problem, a dishonest data provider is a kind of covert adversary who may arbitrarily provide false data on his response attribute. Each data provider who has committed to, when registering, the available attributes is responsible to answer the CS’s challenge request. When the CS detects a data provider cheating, the provider is penalized with a negative weight in the trust score.
- Mutual Authentication: Before the verification process, each data provider and the CS mutually authenticate each other by the TLS 1.2 protocol or higher. It is indispensable for the CS to negotiate on the latest stable version of the TLS protocol and stronger cipher suite to prevent against different forms of deception. After successful authentication of each data provider, they are granted access to the resource queue, where they can register their data attributes.
- Minimal Access for Outsourcing Verification: The data providers who own customers’ private data outsource the verification on their data to the CS. Each data provider computes locally the information gain function on an available attribute, whereas the CS can have access to only an encrypted message, and its keyed hash for the verification. It benefits the data providers to restrict the CS from accessing the customers’ private data. Since encrypted individual data records are not exchanged during the verification, the overhead of computation on the CS is also reduced.
- Authentication and Integrity: HMAC enforces integrity and authenticity. It depends on what underlying hashing function has been used. There are some collision-related vulnerabilities of MD5; however, HMAC-MD5 is not as affected by those vulnerabilities. Regardless, SHA-2 is cryptographically stronger than MD5 and SHA-1. HMAC provides better protection against length extension attacks.
Price Setting Using Auction Mechanism
In the context of quantifying monetary value through sharing person-specific data, the data providers first must do the valuation of personal data, but there is no determined market price for person-specific data that can be taken as a proxy for the valuation. It is also well acknowledged from the existing literature that there is no commonly agreed methodology for valuing personal data. However, in the e-market, many companies actively collect personal information by providing monetary rewards to their customers.
An auction mechanism can be defined in many different ways depending upon the design requirements. The two variants of second price sealed-bid auctions have been widely used, namely, Vickrey-Clarke-Groves (VCG) and generalized second price (GSP) mechanisms for multiple items. The reason for employing the VCG mechanism for determining the pricing on data providers’ attributes is that truthful bidding is a dominant strategy, and there is no incentive to lie or deviate from reporting true valuations for a data provider. It maximizes the total valuation obtained by data providers. One nice property of the VCG mechanism is that it provides a unique outcome, which is socially optimal, whereas, in the GSP, there would be multiple outcomes in terms of Nash equilibrium. One Nash equilibrium would maximize social welfare but not all of them. It is assumed that the data providers intend to set up a matching market using a second price sealed-bid auction for the valuation of their attributes. A reader is referred to the article to see details of the procedure for setting the price.
Privacy Models
In the literature, there are two types of models apprehended: syntactic and semantic. Syntactic models, such as K-anonymity, protect against identity disclosure, l-diversity protects from homogeneity attacks, and t-closeness is an extension of l-diversity, in which the distribution of sensitive attribute values for privacy protection is further refined. Differential privacy, proposed by Cynthia Dwork, is a semantic model that is more robust against the aforementioned attacks. It provides strong privacy guarantees to an individual independently of an adversary’s background knowledge. The intuition of differential privacy is that individual information is not revealed from the output of the analysis in the anonymized data. In other words, it is insensitive whether an individual record is present in the input dataset or not. The article provides an extension of the two-party Differentially private anonymization, which is based on Generalization to differentially integrate multiple private data tables. This algorithm guarantees ϵ -differential privacy and security definition under the semihonest adversary model. The two major extensions over the Top-Down Specialization (TDS) algorithm include: 1) DistDiffGen selects the Best specialization based on the exponential mechanism, and 2) DistDiffGen perturbs the generalized contingency table by adding the Laplacian noise to the count of each equivalence group.
Monetary Share Under ϵ-Differential Privacy Mechanism
Monetary share is the profit earned by a data provider based on the contribution to the information utility over the differentially private integrated data and the trust score. Privacy budget ϵ and specialization level h are the parameters of the differentially private (DistDiffGen) algorithm. The information utility varies with the valuations of data providers' attributes and joint privacy requirements, such as privacy budget ϵ and specialization level h, for a ϵ-differential privacy model in a distributed setup, between the data providers. ϵ is the privacy budget that is specified by the data custodian. A smaller value of ϵ results in stronger privacy protection but produces lower data utility. Conversely, a larger value of ϵ results in weaker privacy protection but yields higher data utility. Rationally, the privacy control parameters influence the monetary value.
What are the benefits of the approach, and what lesson have we learned?
A novel entropy-based trust computation algorithm is proposed to verify the correctness of data from untrusted multiple data providers who own overlapping attributes over the same set of records. The three main benefits are achieved in delegating the verification role to the semi-trusted CSP. First, the proposed method ensures that the CSP cannot derive customers’ private data from the information collected during the verification process. Second, the overhead of computation on the CS is also reduced because only an encrypted information gain message and its keyed hash are exchanged between a data provider and the CS, instead of exchanging encrypted individual data records during the verification process. Third, it also reduces the burden on data consumers to determine which data providers can serve their demands on requested attributes and what are their attained trust scores. Furthermore, the robustness of the approach is evaluated when an acquisitive data provider employs the machine learning method for imputation of missing values on its data in order to claim it as original data. The VCG auction mechanism is incorporated to determine the pricing on data providers’ attributes. It maximizes the total valuation obtained by data providers since there is no incentive to lie or deviate from truthful reporting for a data provider. The data providers who are accepted after the trust computation phase set their joint privacy requirements for the data mashup. During the mashup process, every data provider competes with all the other participating data providers to produce more data utility. The data provider, whose data attributes result in more information gain and whose trust level is higher than the other competitors, can get a proportionally large share of the monetary value.