
Learning AI with NO Data: No more Data Problem? (One-shot learning AND Less than One-shot learning)
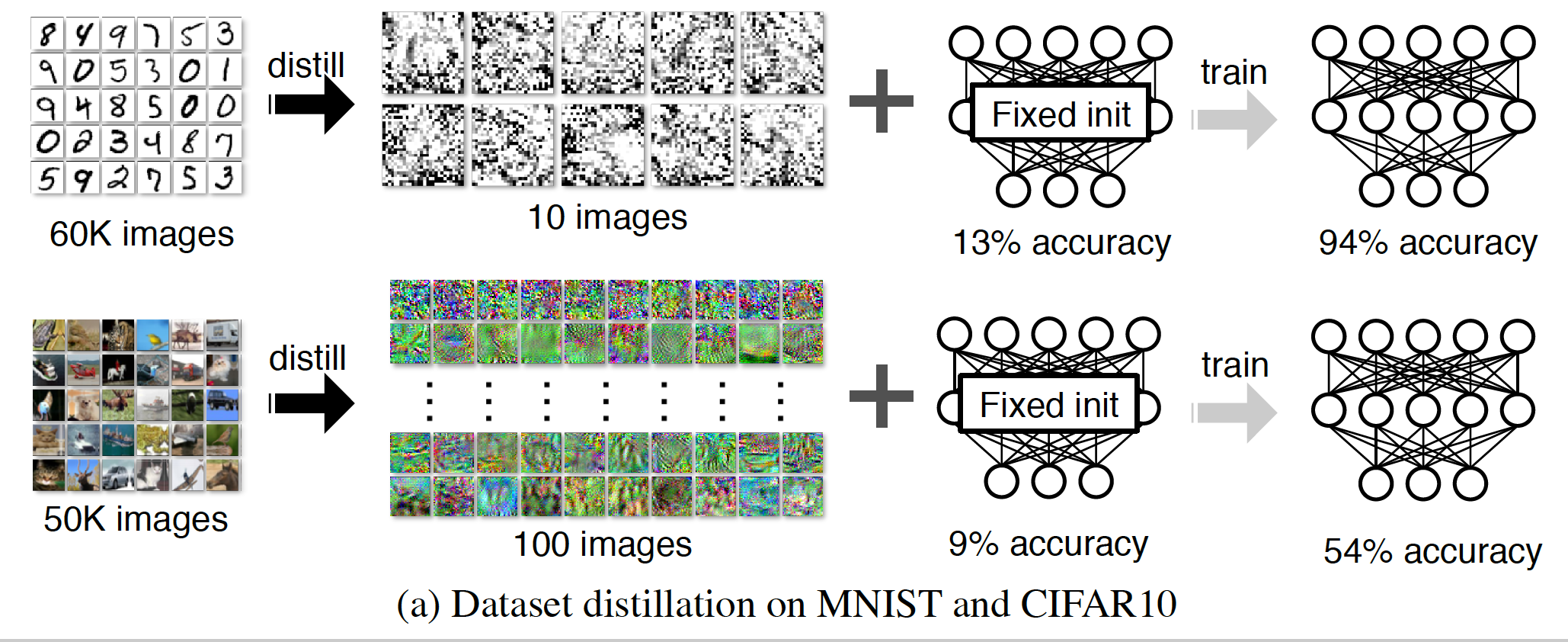
Unlike humans, deep supervised algorithms and machine learning techniques require several objects to learn. A child usually needs to perceive just a few examples of an object or even only one before recognizing it for life. By displaying photos of a horse and eagle and telling the child there is a magical creature in between called a unicorn, they can recognize it anywhere they see it. The question is, how can we program AI to be the same? A couple of MIT researchers proposed a distillation technique that synthesizes a small number of data points that do not need to come from the correct data distribution. Their experimental result illustrated that their model could compress 60,000 MNIST training images into only 10 images (one per class).

Ummm still not a unicorn…
How to make the program react like a Child? A couple of MIT researchers proposed a distillation technique. Model distillation intends to refine the knowledge of a complex model into a simpler one. They consider an alternative formulation called dataset distillation: in their model, they keep the model fixed instead of distilling the knowledge from a large training dataset into a small one. " The idea is to synthesize a small number of data points that do not need to come from the correct data distribution, but will, when given to the learning algorithm as training data, approximate the model trained on the original data." Their experimental result illustrated that their model could compress 60,000 MNIST training images into only 10 images (one per class). The impressive bit is these 10 images achieve close to the actual performance of training an ML model with 60,000 instances.
Is something called” One-shot learning” the solution?
One-shot learning is a classification or object categorization task in which one or a few examples are used to classify many new examples. As mentioned before, deep learning models do not react well to a small number of samples, especially when it comes to image processing tasks such as face recognition. Different factors such as the age of the person, lighting, background, other expressions can cause influence the result of the face recognition method, and having a small number of data does not help.

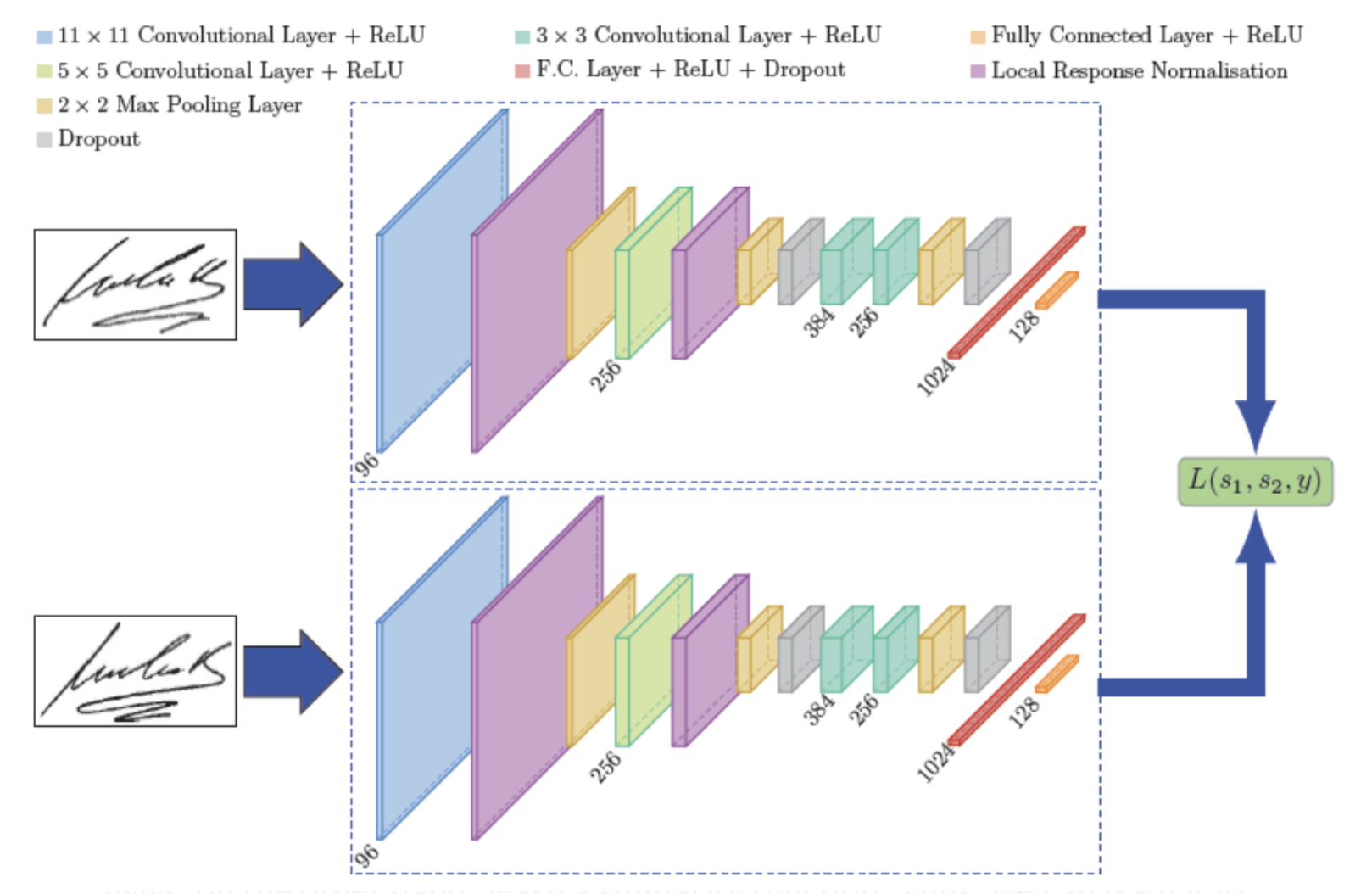
There are different one-shot learning solutions. Triplet loss integration, the Siamese networks, and Contrastive loss for dimensionality reduction follow the aspect of one-shot learning. Siamese networks are based on a similarity function. There are two parallel neural networks in terms of architecture, each taking a different input and whose outputs are combined to provide a prediction.
“A Siamese Neural Network is a class of neural network architectures that contain two or more identical subnetworks. ‘identical’ here means, they have the same configuration with the same parameters and weights. ”
Less than One-shot learning (LO-shot learning)
The researcher from the University of Waterloo aimed for something more adventurous. They tried to compress the 60,000 images to even four images this time by utilizing the same distillation process. In other words, they try to create something that contains multiple digits and then fed them to the AI model. In the few-shot learning setting, a model must learn a new class given only a small number of samples from that class. One-shot learning is an extreme form of few-shot learning where the model must learn a new class from a single example. They proposed a ‘less than one’-shot learning task where models must learn N new classes given only M < N examples and we show that this is achievable with the help of soft labels. They use a soft-label generalization of the k-Nearest Neighbors classifier to explore the intricate decision landscapes created in the ‘less than one’-shot learning setting.
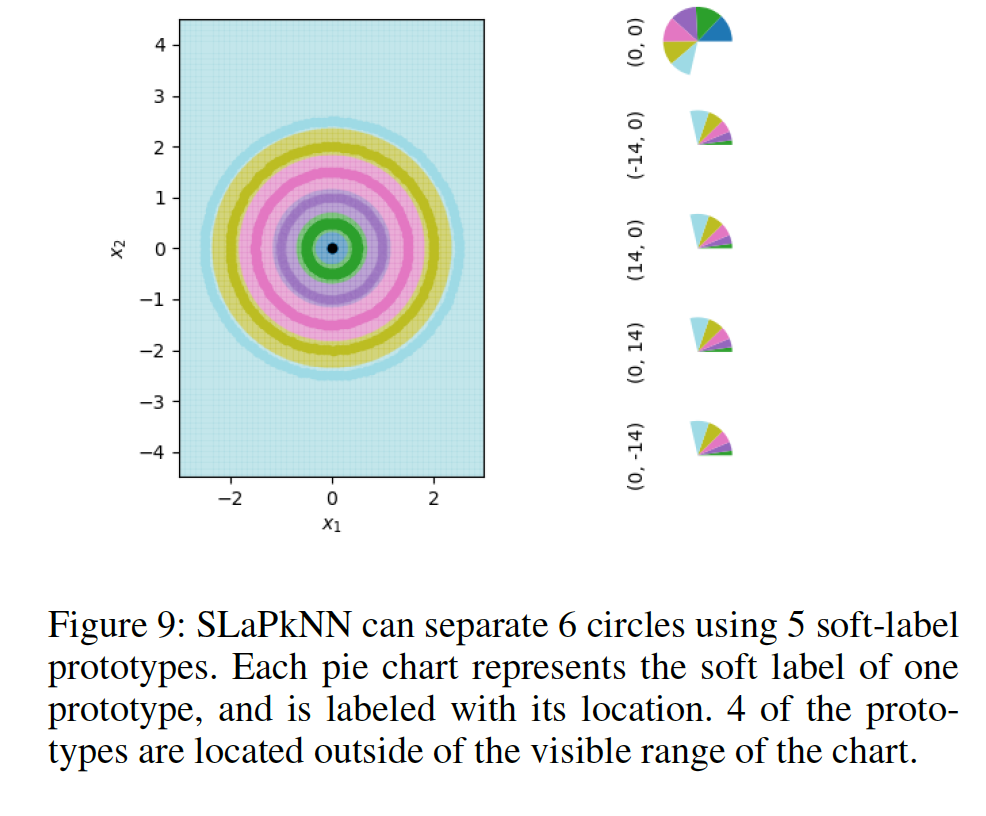
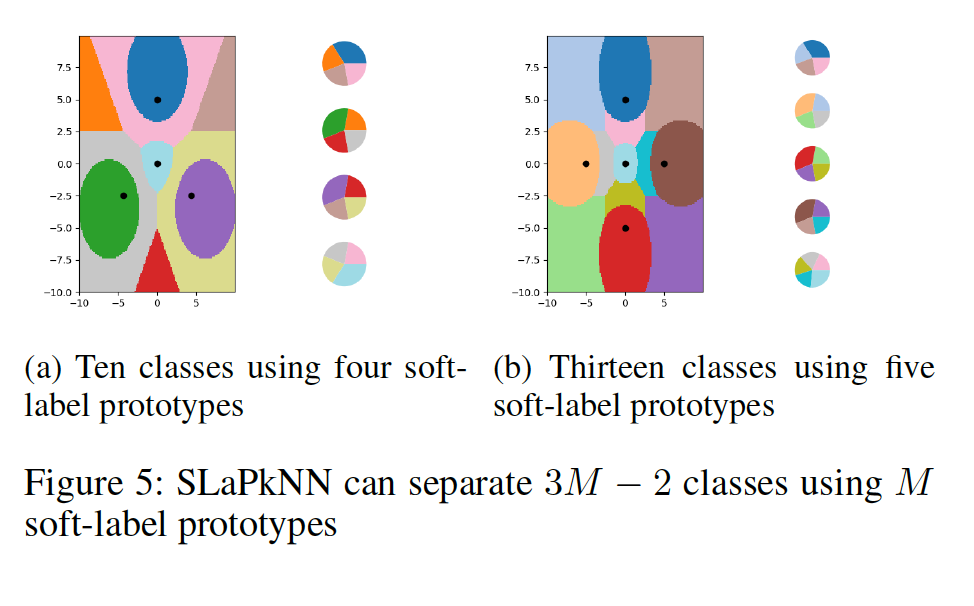
“A setting where a model must learn N new classes given only M < N examples, less than one example per class. At first glance, this appears to be an impossible task, but we both theoretically and empirically demonstrate feasibility. As an analogy, consider an alien zoologist who arrived on Earth and is being tasked with catching a unicorn.” In particular, this unintuitive setting relies on soft labels to encode and decode more information from each example than is otherwise possible. An example can be seen in Figure 1 where two samples with soft labels are used to separate a space into three classes. To investigate LO-shot learning with the kNN algorithm, the researchers performed a range of small artificial data sets and carefully managed their soft labels. Then they let the kNN plot the boundary lines it was seeing and found it successfully split the plot up into more classes than data points.
The authors are working on showing that LO-shot learning is compatible with a large variety of machine learning models. They believe “deep learning models such as deep neural networks would benefit more from the ability to learn directly from a small number of real samples to enable their usage in settings where little training data is available.” . However there is still major challenge and big research question which really depends on the type of dataset.