
Understanding the Model Context Protocol and Its Cybersecurity Risks
Artificial intelligence models are no longer isolated text generators. They are turning into autonomous agents that schedule meetings, read files, execute code, trade stocks, and reach into corporate systems. As these capabilities grow, so does the need for a consistent and secure way for models to interact with external tools. The Model Context Protocol (MCP), introduced by Anthropic in late 2024, has quickly emerged as the major standard for connecting Large Language Models (LLMs) to tools, APIs, and live business systems. MCP makes agentic AI far more powerful, but it also opens new attack surfaces that are only beginning to be systematically studied in academic and industry security research. This article explains how MCP works, why it emerged, and what its cybersecurity implications are.
From LLMs Working Alone to Tool-Using Agents
Before and early 2023, LLMs worked in isolation. They generated ideas and explanations, but they could not interact with the real world. They could not fetch live weather, query databases, read files, or place online orders. The only input they received was text, and the only output they produced was text. As a result, they were rarely used to automate workflows in any meaningful way. Research during this period, such as the early GPT-3, LLaMA-1, and PaLM models, focused more on scaling and training than on integration with external systems. [1, 2, 3]
Traditional Large Language Models (LLM)
By 2023, developers began connecting LLMs to APIs manually. Projects like OpenAI Plugins, LangChain tools, and custom Python integrations showed that models could perform real actions if developers wrapped each API by hand. But this approach created major engineering problems. Every application had to reinvent the integration layer, define its own JSON schema, handle authentication manually, and manage complex security logic. Companies wasted enormous time building the same wrappers repeatedly, and the lack of standardization made auditing and securing LLM-driven tools extremely difficult. Research highlighted how bespoke tool integrations created overlapping but inconsistent risks. [4]
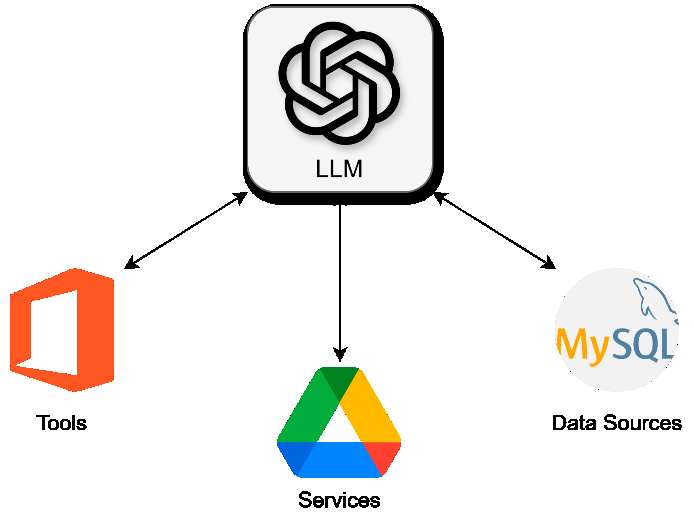
LLMs with manual API integration
The need for a universal standard became obvious. MCP emerged to solve this: one protocol that any tool, database, file system, or service can implement, and any LLM agent can understand. Instead of wiring APIs separately, companies can expose them through MCP servers, which advertise capabilities, schemas, resources, and tools to the client in a consistent, machine-readable format. This reduces duplication dramatically but raises equally dramatic cybersecurity questions.
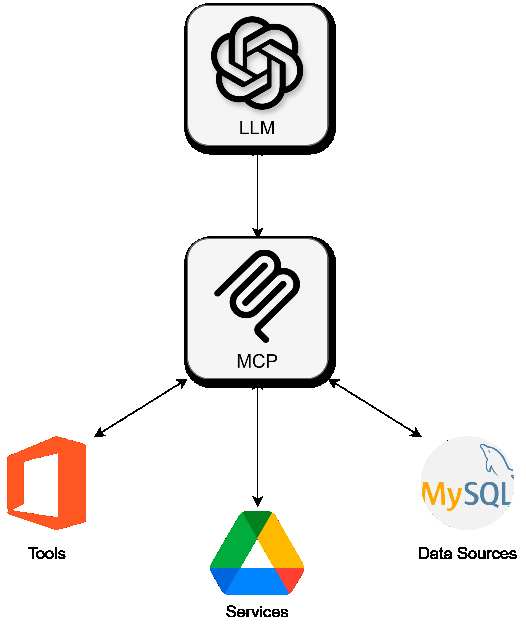
LLM augmented with MCP
How the Model Context Protocol Works
MCP is built on top of JSON-RPC 2.0 and uses a simple architecture: a client (the LLM host or agent system) connects to a server (a wrapper around tools or resources). Communication happens over standard channels such as stdio and Streamable HTTP, and implementations can optionally add custom transports (for example, WebSockets or raw TCP) as long as they carry MCP JSON-RPC messages. [5] When the client initializes the connection, the server advertises its capabilities and implementation details. The client then queries the server for the available tools, resources, and prompts, including their schemas, so the model can decide what to call. The LLM can then call these tools using structured RPC messages.
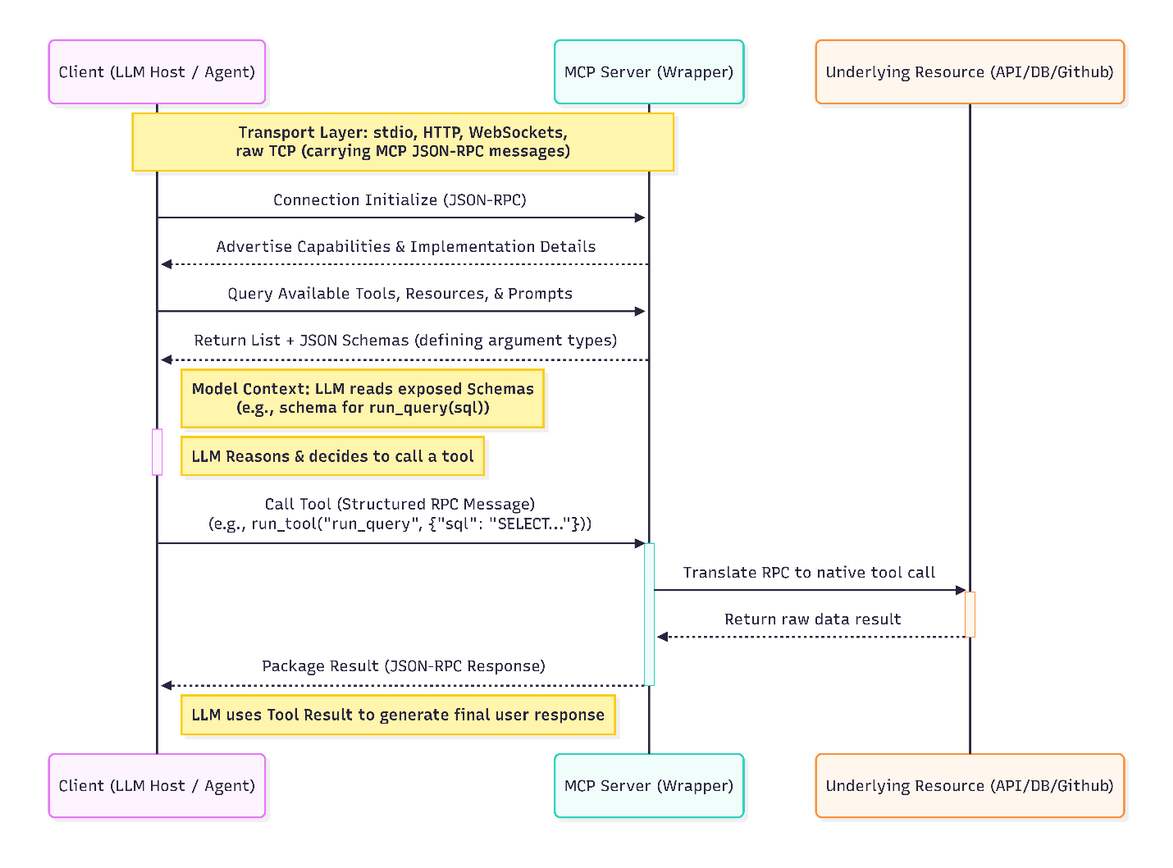
In practice, this means an LLM does not need custom code to know how a weather API, a GitHub repository, or a SQL database works. These integrations are packaged into MCP servers that expose functions like get_weather(city) or run_query(sql) along with JSON schemas describing argument types. The model reads these schemas, reasons about them, and decides which tools to call. The protocol is intentionally simple, designed for both local and remote use, and intended to be widely adopted across open-source and commercial systems.
This simplicity is part of MCP’s strength, but also where many security concerns begin.
Security Implications at the Protocol Level
At the protocol layer, MCP focuses on structured communication and is transport-agnostic. The base JSON-RPC layer does not itself carry authentication or encryption, and security depends heavily on the surrounding environment. For HTTP-based transports such as Streamable HTTP, the MCP specification defines an OAuth-style authorization framework and recommends that servers enforce authentication over secure transports (HTTPS/TLS). [6] In practice, however, whether any given MCP deployment is authenticated or encrypted still depends on how developers configure the surrounding infrastructure. If developers skip these mechanisms or misconfigure them, an MCP deployment can still end up effectively unauthenticated or unencrypted. The protocol trusts that the endpoints are legitimate and focuses only on structured communication. As a result, if a developer accidentally connects to a malicious MCP server, either through a typo, a misleading package name, or an intentionally deceptive distribution, the client will accept the server’s advertised tools without question.
Protocol-level risks include schema manipulation, command injection within argument validation, and tool-chaining abuse, where a malicious server advertises multiple benign-looking functions that, when executed in sequence, lead to unintended operations. Recent research shows that LLMs can be induced to misuse tools when exposed to adversarial tool descriptions, prompts, or metadata, even when each tool appears benign in isolation. [7, 8] MCP’s assumption that schemas and descriptions are honest creates room for attackers to manipulate the model’s planning. Because MCP assumes that schemas are honest, the protocol unintentionally creates room for attackers to manipulate the LLM’s planning.
MCP still lacks a built-in mechanism for cryptographic server provenance or signature verification. Although an official MCP server registry and several third-party directories now exist, they function primarily as discovery and listing services rather than providing end-to-end, protocol-level guarantees that a given server is trustworthy. This means the protocol is secure only if the environment around it is secure.
Security Risks Introduced by the MCP Server
Every MCP server exposes tools, and every tool represents an attack surface. A malicious or compromised server can advertise functions that appear harmless but perform dangerous actions under the hood. For example, a server claiming to provide weather information could also read files from disk when the model passes a specific argument pattern. The LLM has no way to inspect server code; it trusts tool descriptions.
MCP servers also handle sensitive secrets. They often need API keys, OAuth tokens, database passwords, and cloud credentials in order to execute real operations. [9] If a server is compromised or deliberately designed to be malicious, those secrets can be leaked. This mirrors traditional API supply-chain risks but amplifies them, as LLM-driven automation may repeatedly call or chain tools without human oversight.
Additional risks arise from dynamic tool behavior. A server can change its schema after the initial handshake, offer tools that are not documented, or behave differently based on the context sent by the LLM. This opens attack vectors such as tool poisoning, rug-pull attacks, and resource-shadowing, where a server pretends to provide one resource but accesses another.
The MCP server is, in short, a powerful but potentially untrusted execution environment.
Security Risks on the Host / Client Side
Even if the protocol is clean and the server is well-implemented, the host (the LLM or agent client) introduces its own security challenges. Models do not evaluate server trustworthiness. They do not understand malicious intent. They simply read schemas and attempt to satisfy the user’s request using the tools available. [10]
If the model incorrectly reasons about the server’s capabilities, it may perform destructive actions such as deleting files, sending data to the wrong API, exposing system paths, or retrieving sensitive configuration details. Studies reveal that models are highly sensitive to adversarial prompts and tool definitions. [11] A single malicious server response can cause the model to use the wrong tool or include sensitive internal information in later messages.
The client is also vulnerable to preference manipulation, where a server subtly shapes its responses or tool metadata to bias how the model chooses among multiple tools. [12] Over time, a malicious server can significantly increase the likelihood that the model selects its own tools, effectively establishing a persistent foothold in the agent’s workflows. Without strict allow-lists, per-tool permissions, and usage boundaries, the client becomes the execution engine for attacker-controlled actions.
Conclusion
MCP is an important and necessary evolution in the AI ecosystem. It solves a real engineering problem by giving LLMs a unified way to interact with tools and data sources. It dramatically reduces redundancy, simplifies integration, and enables a future where agentic AI can automate complex workflows safely and consistently. However, the protocol is young, and its security model is thin. Its simplicity creates new risks at every layer: the core protocol still provides no built-in provenance guarantees, authentication depends heavily on the chosen transport and developer configuration, MCP servers may be malicious or compromised, and the client-side reasoning of LLMs remains unpredictable in the face of adversarial or misleading tool descriptions.
Securing MCP will require more than best practices. It will require new infrastructure: verification layers, proxies that validate tool behavior, MCP-aware security scanners, secret management frameworks, and policy engines that limit what agents are allowed to do. As adoption grows, these tools will become as essential as firewalls were to the early internet.
Edited By: Windhya Rankothge, PhD, Canadian Institute for Cybersecurity
References
[1] Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901. https://arxiv.org/abs/2005.14165
[2] Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023). https://arxiv.org/abs/2302.13971
[3] Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham et al. "Palm: Scaling language modeling with pathways." Journal of machine learning research 24, no. 240 (2023): 1-113. https://arxiv.org/abs/2204.02311
[4] Greshake, Kai, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. "Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection." In Proceedings of the 16th ACM workshop on artificial intelligence and security, pp. 79-90. 2023. https://arxiv.org/abs/2302.12173
[5] Model Context Protocol (MCP), Base Protocol Transports, https://modelcontextprotocol.io/specification/2025-11-25/basic/transports
[6] Model Context Protocol (MCP), Base Protocol Authorization, https://modelcontextprotocol.io/specification/2025-11-25/basic/authorization
[7] Fu, Xiaohan, Zihan Wang, Shuheng Li, Rajesh K. Gupta, Niloofar Mireshghallah, Taylor Berg-Kirkpatrick, and Earlence Fernandes. "Misusing tools in large language models with visual adversarial examples." arXiv preprint arXiv:2310.03185 (2023). https://arxiv.org/abs/2310.03185
[8] Zhang, Rupeng, Haowei Wang, Junjie Wang, Mingyang Li, Yuekai Huang, Dandan Wang, and Qing Wang. "From allies to adversaries: Manipulating llm tool-calling through adversarial injection." In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 2009-2028. 2025. https://arxiv.org/abs/2412.10198
[9] Managing Secrets in MCP Servers, https://infisical.com/blog/managing-secrets-mcp-servers
[10] Shi, Jiawen, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. "Prompt injection attack to tool selection in llm agents." arXiv preprint arXiv:2504.19793 (2025). https://arxiv.org/abs/2504.19793
[11] Li, Miles Q., and Benjamin CM Fung. "Security concerns for large language models: A survey." Journal of Information Security and Applications 95 (2025): 104284. https://arxiv.org/abs/2505.18889
[12] Wang, Zihan, Rui Zhang, Yu Liu, Wenshu Fan, Wenbo Jiang, Qingchuan Zhao, Hongwei Li, and Guowen Xu. "Mpma: Preference manipulation attack against model context protocol." arXiv preprint arXiv:2505.11154 (2025). https://arxiv.org/abs/2505.11154