
Understanding LLM Performances: Loss Functions and Model Evaluation
Understanding how Gen-AI models, particularly large language models (LLMs), learn requires examining their behavior both during training and after training is complete. During this process, loss functions play a central role by showing how far the model’s predictions are from the correct outputs. A lower loss generally means the model is making better predictions, while a higher loss indicates more mistakes. Tracking this value over time helps us understand whether the model is actually learning or struggling. These metrics provide a clearer picture of how well the model generalizes to new, unseen data, beyond the training set.
1. What Are Loss Functions for LLMs?
In most LLMs, the primary loss function used during training is cross-entropy loss. Cross-entropy measures how well the predicted probability distribution over tokens matches the true target token. If the model assigns a high probability to the correct next token, the loss is low; if it assigns a low probability, the loss is high.
In practice, modern frameworks such as Hugging Face simplify this process. For example, models loaded with AutoModelForCausalLM automatically compute the cross-entropy loss during training when labels are provided. This makes cross-entropy the default and most widely used loss function for training autoregressive LLMs.
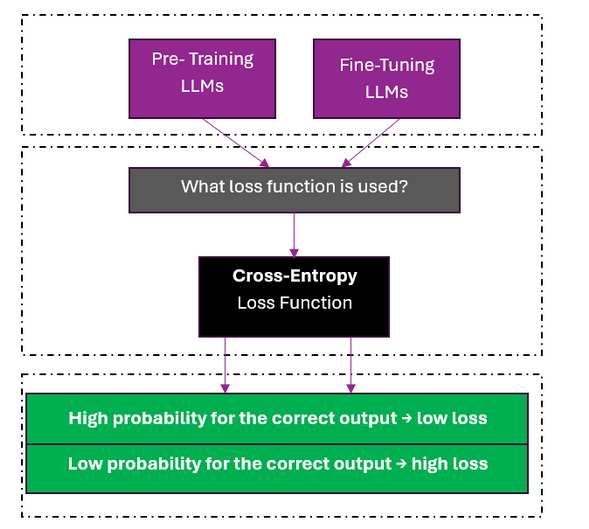
Fig1. Cross-Entropy is the most common loss function for LLMs.
2. Which Evaluation Metrics Should Be Used for Different LLM Tasks?
The choice of evaluation metrics depends heavily on the task the LLM is designed to perform. For text generation tasks, such as natural language description or summarization, similarity-based metrics are commonly used. Metrics like BLEU measure n-gram overlap between generated text and reference text, while BERTScore compares semantic similarity using contextual embeddings. For other tasks, such as classification or question answering, different metrics may be more appropriate, including accuracy, precision, recall, or F1-score. These metrics help evaluate whether the model produces correct and consistent outputs for a given task.
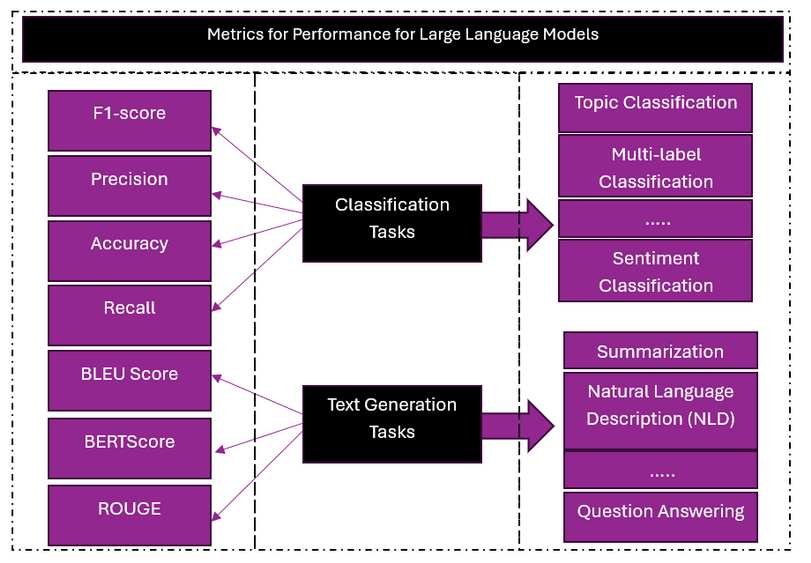
Fig 2. Different LLM tasks require different standard evaluation metrics.
3. When and Which Metrics to Use for LLMs
There is no single metric that works for all LLM use cases. The choice of metrics should be guided by the task type, application goal, and expected model behavior. For example, generation tasks benefit from semantic similarity metrics, while decision-making or classification tasks require correctness-focused metrics. Understanding the LLM problem and the evaluation objective is essential for selecting suitable metrics. Choosing the right metrics ensures that the model is evaluated in a way that aligns with real-world requirements and practical expectations.
4. Conclusion
LLMs as a GenAI model like other neural language models, use cross-entropy loss function during training. Loss functions and evaluation metrics are essential for understanding how LLMs learn and how well they perform. Loss functions help guide the model during training by showing how far its predictions are from the correct answers, while evaluation metrics are used afterward to check how well the model works on new, unseen data.
Edited By: Windhya Rankothge, PhD, Canadian Institute for Cybersecurity
Reference:
1 .Ciampiconi, L., Elwood, A., Leonardi, M., Mohamed, A., & Rozza, A. (2023). A survey and taxonomy of loss functions in machine learning. arXiv preprint arXiv:2301.05579. http://arxiv.org/abs/2301.05579
2. Hu, T., & Zhou, X. H. (2024). Unveiling llm evaluation focused on metrics: Challenges and solutions. arXiv preprint arXiv:2404.09135. https://arxiv.org/abs/2404.09135
3. Gao, M., Hu, X., Yin, X., Ruan, J., Pu, X., & Wan, X. (2025). Llm-based nlg evaluation: Current status and challenges. Computational Linguistics, 1-27. https://arxiv.org/abs/2402.01383